Dropout reducing under fitting
arxiv:https://arxiv.org/pdf/2303.01500v1.pdf
Author:张一极
date:2023年03月04日14:31:23
Dropout是一种由Hinton等人在2012年提出的正则化技术,用于防止神经网络的过拟合。
文章来自 facebook ailab,作者团队在本研究中证明了在训练开始时使用dropout还可以缓解欠拟合的问题。
他们发现,小数据量,和小模型都会造成过拟合,主要现象是,测试数据和训练数据的精度差异越来越大:
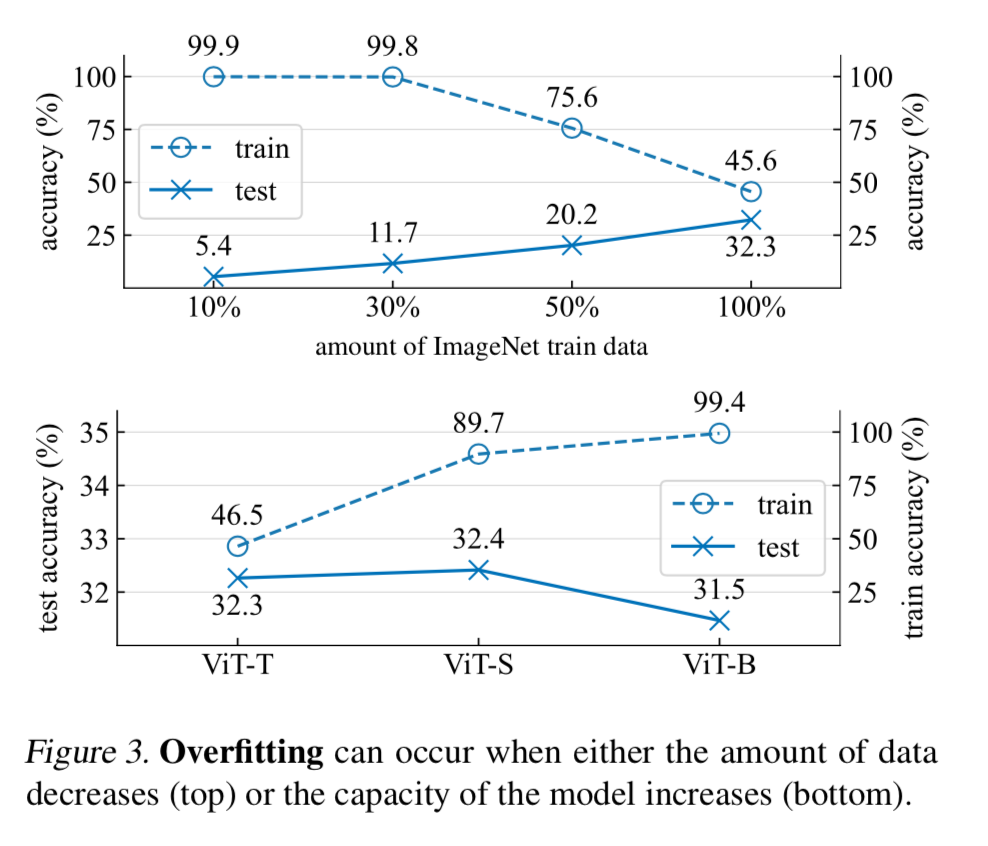
在早期阶段,作者发现dropout减少了小批量间梯度的方向差异,并帮助使小批量梯度与整个数据集的梯度保持一致:如下图
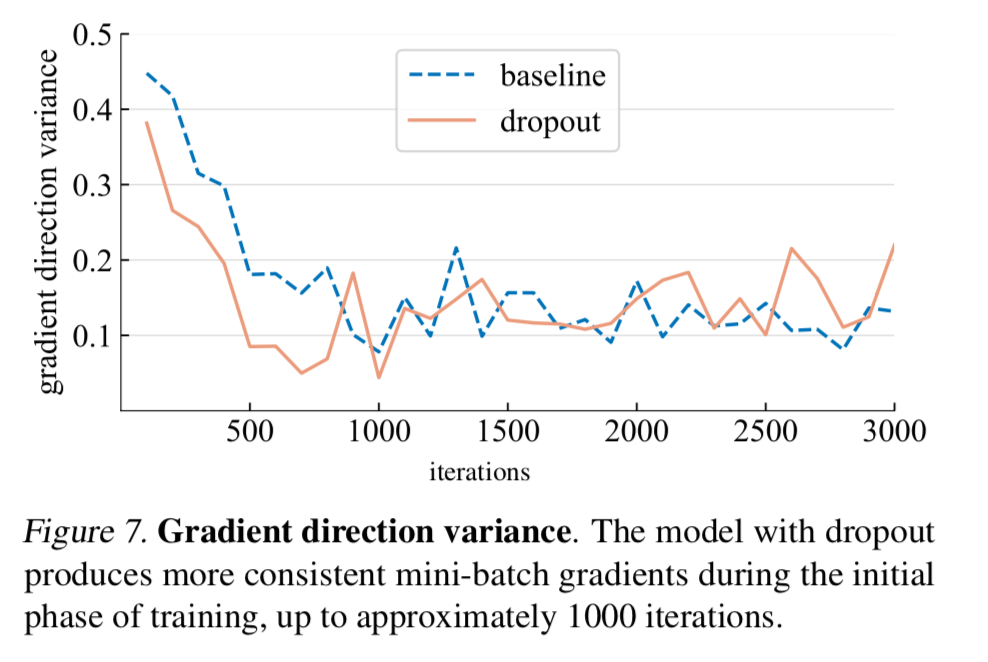
这有助于抵消SGD的随机性,并限制单个批次对模型训练的影响。
他们用以计算梯度差异的方法是,设置检查点来查验收集一个 minibatch 的梯度,然后计算平均余弦距离来计算梯度 diff:
顺便取了整个数据集的应有梯度,用以评估整体梯度的方向差异:
作者团队计算了这个误差,并且放到了整张 training step 的图像上进行比对:
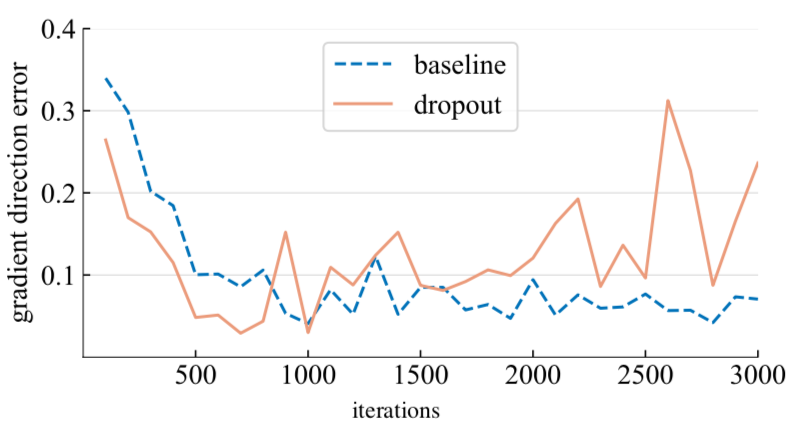
结果就是,带 dropout 的 training 过程中产生的梯度水平和整个数据集的差异较小,经过 1000 次迭代后,带 dropout 的模型,产生了所谓的 gradients that are farther away,这就是从欠拟合到过拟合的拐点。
原文:
After approximately 1000 iterations, however, the dropout model produces gradients that are farther away. This could be the turning point where dropout transitions from reducing underfitting to reducing overfitting.
作者的研究结果为改善欠拟合模型的性能提供了一个解决方案,就是早期使用dropout:只在训练的初始阶段应用dropout,并在之后关闭它。
与没有dropout的对照模型相比,配备早期dropout的模型实现了更低的最终训练损失。
我们都知道,SGD的梯度统计规则是根据每一个 batch 来的,即通过每一个 minibatch 获得整个数据集梯度的无偏估计,而通过 dropout 的梯度,会变得有点偏差,尽管有偏差,但是梯度方向会因为 dropout 得到修正,有助于防止模型过拟合和欠拟合。
if a model generalizes better with standard dropout, we consider it to be in an overfitting regime; if the model performs bet- ter without dropout, we consider it to be in an underfitting regime. The regime a model is in depends not only on the model architecture but also on the dataset used and other training parameters.
关于 dropout 的比例:
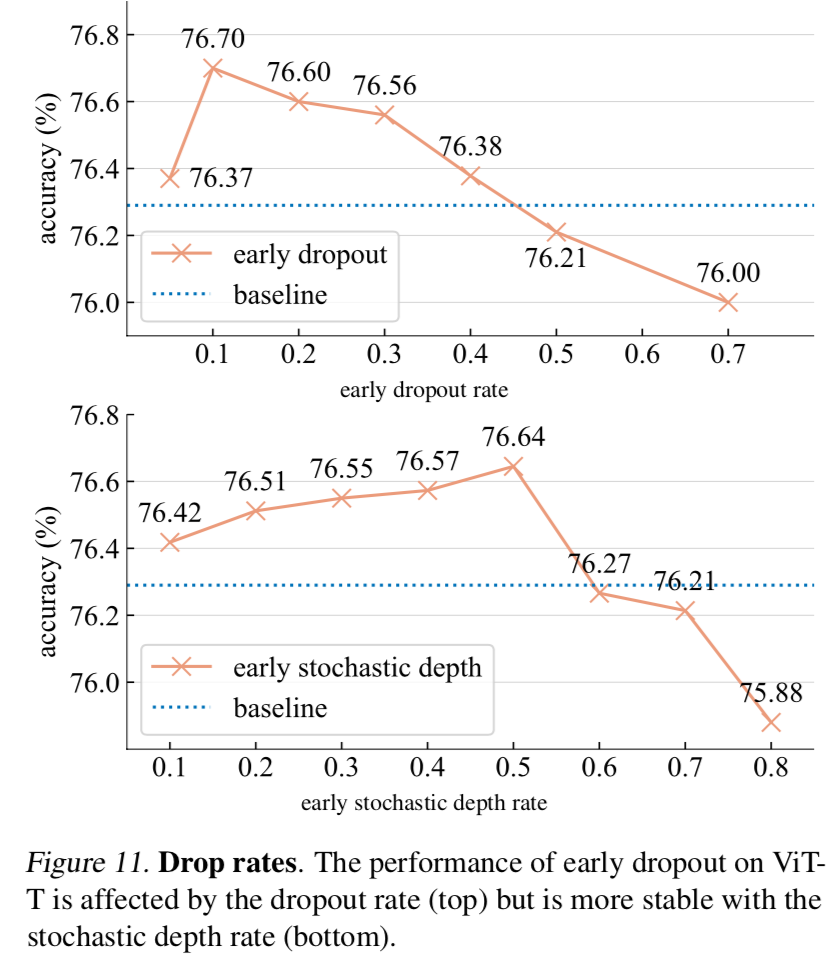
实验结果:
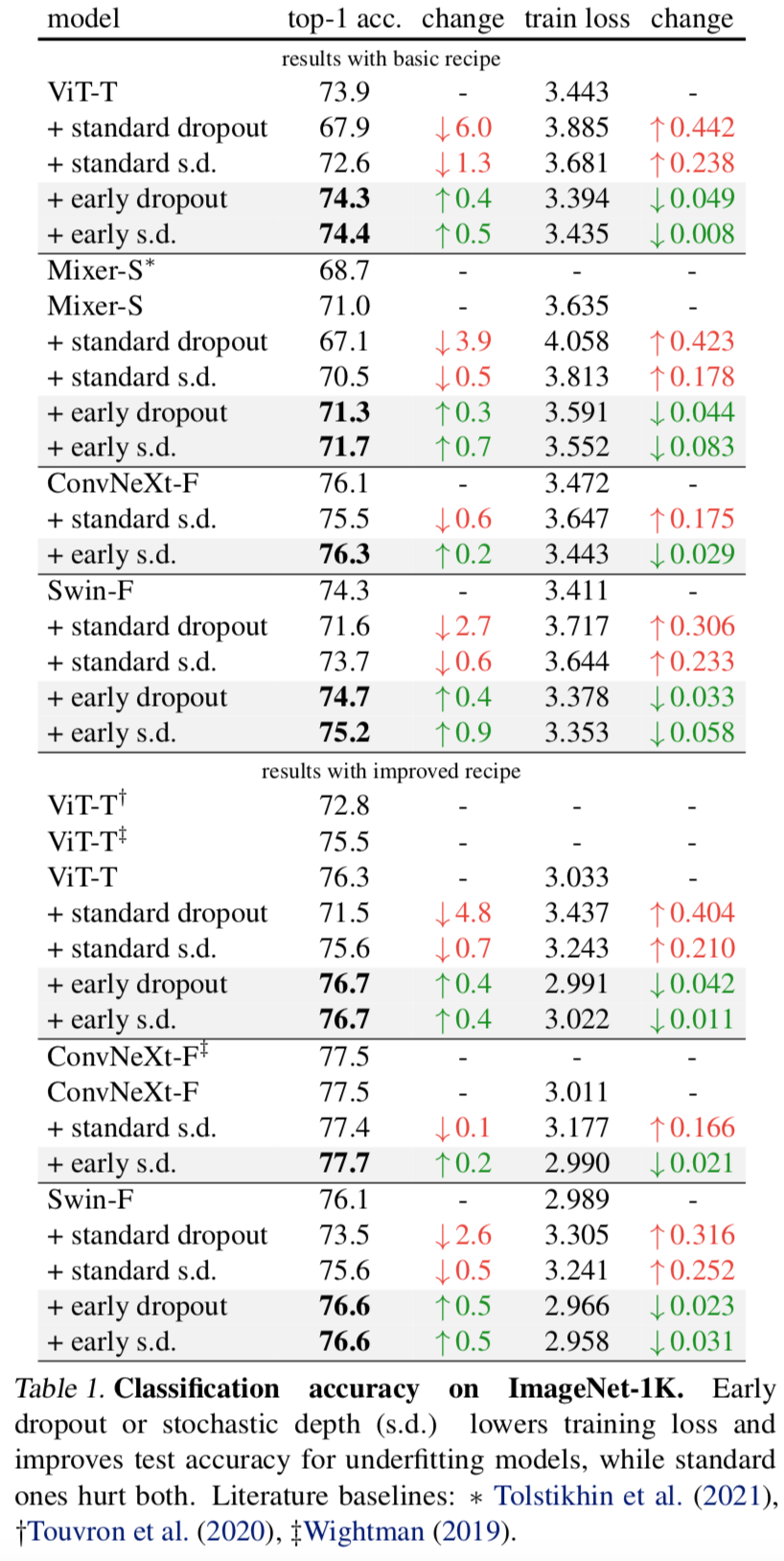
此外,作者探索了一种对过拟合模型进行正则化的对称技术 - late dropout,即在早期迭代中不使用dropout,而只在训练后期激活。在ImageNet和各种视觉任务上的实验表明,作者的方法始终提高了泛化精度。作者的研究结果鼓励更多关于深度学习中正则化的研究,并且作者的方法可以成为未来神经网络训练的有用工具,特别是在数据爆炸增长的时候,大多数的冗余数据,可以在合适的正则策略中,得到更好的优化和学习。
作者也做了关于其他下游任务的消融实验:
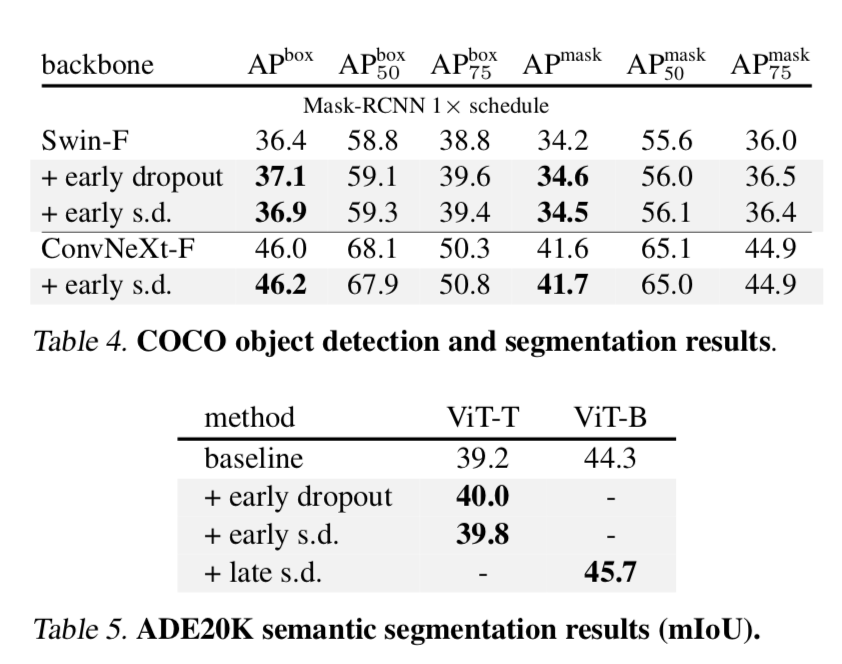
总结:建议早期使用 dropout ,在训练中途关闭它,以及在快结束前使用late dropout,进行模型正则化,且使用较低的 dropout 比例(0.1-0.3)。