NAS
Author:张一极
2020-0127-1:55
主要结构和强化学习优化算法的推导
NAS目前主要分为了三个部分的内容
搜索空间
首先是网络在搜索空间里采样出一个子网络结构,而后交给性能评估函数进行评估,返回结果后按照网络性能进行梯度估计和参数更新
重新采样网络,Step by Step的一个过程
搜索空间包括但不限于:DilConv,conv,pooling,bn,SepConvNxN(多DilConv),Fc,skip-connect等op的一些操作,定义了网络的基本算子
搜索策略
随机(random)
RL(主流)
评估指标
精度期望(单次精度波动存在且不确定)
RL的梯度计算:
RNN作为控制器,每一次循环输出一个网络结构及其参数(多网络,主流方法是一个网络采样一种基本结构,两种网络采样两个结构作为基本的block),然后不同堆叠,组成子网络。
细节:因为每一个子网络在数据集上的表现波动很大,而进行多次实验的资源很浪费,故而使用子网络在数据集上的精度期望作为评价指标,(大数定律表明多次实验的结果依照概率收敛于期望),我们使用对于精度的无偏估计作为指标,,表示子网络在验证数据集上的精度期望,L的直观感受就是,精度期望越高,生成概率越高。
得到,代表为参数的p分布下,生成的网络在数据集上的精度期望,这个期望越高,代表其效果越好,另一种表达方式是,一个序列动作中,即一连串的网络结构中,每一个结构获得的reward最终加和得到最后的期望。
梯度计算过程:
我们定义好整个序列动作和reward为,这部分的R代表了整个序列动作得到的所有reward,但是有时候的情况是,动作序列和得到的reward有很多很多种,无法穷举计算,这时候我们一般采用大数定律做一个概率性的收敛得到一个估计值:,这个估计值代表了在次的实验下,每一次实验得到的reward和出现这个结果的概率,这是可以穷举的,所以我们在这里做了一个近似。
我们的目的,就是最大化这个,我们就需要知道他的梯度。
首先,这个函数对参数的一阶导的话,第一项是没有意义的,因为和参数无关,只和动作结果有关,只需要对第二项微分即可:,接着我们对这个函数作如下变形,为了得到一个关于P的式子,,利用,得到,前半部分,可以使用概率似然估计为。
・
取对数得到:
其中与数据集的难易程度有关,与参数其实无关,顾仅有的一部分为,由此可得:
为了解决REINFORCE算法计算出的梯度值偏差问题,在计算梯度时减掉了均值b,最终得到的梯度函数为:
如果用来表述的话,即:,m为小batch的个数,N是线性串型网络的层数,此方法只能用于生成无跳层连接和concat的网络结构,计算量较大,有两种可以解决的方案,一种解决方案是对搜索空间进行裁切,固定某几种网络结构作为基本类型,堆叠成重复的网络结构,可以得到很多经典网络(Resnet,inception...)(来自Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. ICLR 2016.)
以下是NASnet和ENAS的一些结构和训练细节。
NASnet
结构
NASnet采取了这样的解决方案,推理出基本模块,进行堆叠,在小数据集上训练(mini-cifar),最后tranfer到imagenet上,Controler预测的是基本两种网络block,分别称为Normal Cell和Reduction Cell,适应不同特征层尺寸需要,因为我们的图像在数据流中需要做一些变化去获取不同尺寸的特征,normal cell不改变图像尺寸,reduction cell将图像尺寸减半,适应于tranfer learning的需要(不同scale的img输入流),
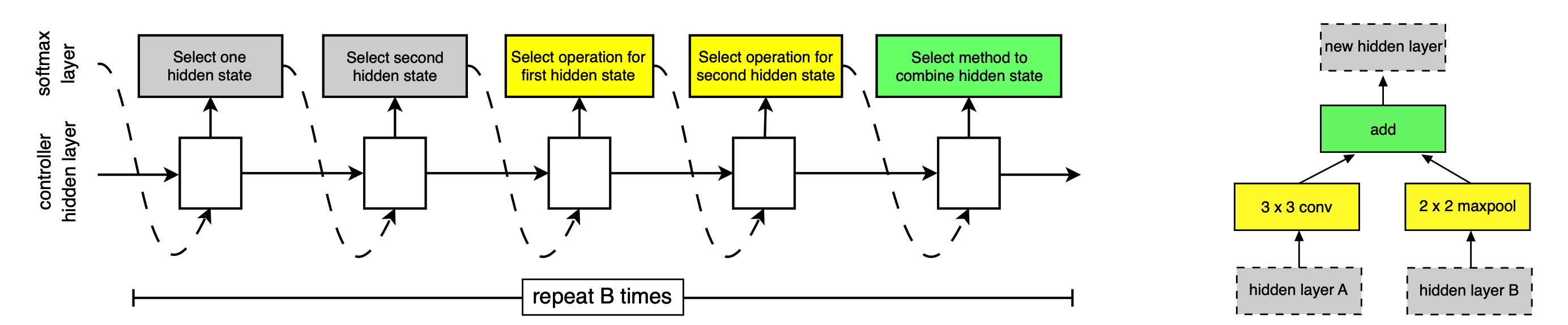
NASnet在原来的基础上,做了一个新的事情,就是更改了搜索空间和堆叠策略,改为搜索两个基本结构,普通的cell没有改变特征图大小的功能,Reduction Cell会改比那图像尺寸,通过一个序列神经网络,分别预测两种结构(一种网络预测两种结构),每一个神经元的输出做不同的事情第一个为网络选择一个隐含状态作为第1个输入,第二个选择一个隐含状态作为第二个输入,第三个神经元选择为第一个隐含状态(前面层的输出结果)做运算(激活,池化,卷积),第四个同理激活第二个隐含层的输出,最后为两个计算结果选择合并方式,合并得到一个输出。
如下:

(1) 选择一个隐含状态作为第1个输入
(2) 选择一个隐含状态作为第2个输入。 (3) 为第1个隐含状态选择一个运算。 (4) 为第2个隐含状态选择一个运算。 (5) 为两个运算的结果选择一个合并方式,执行合并。
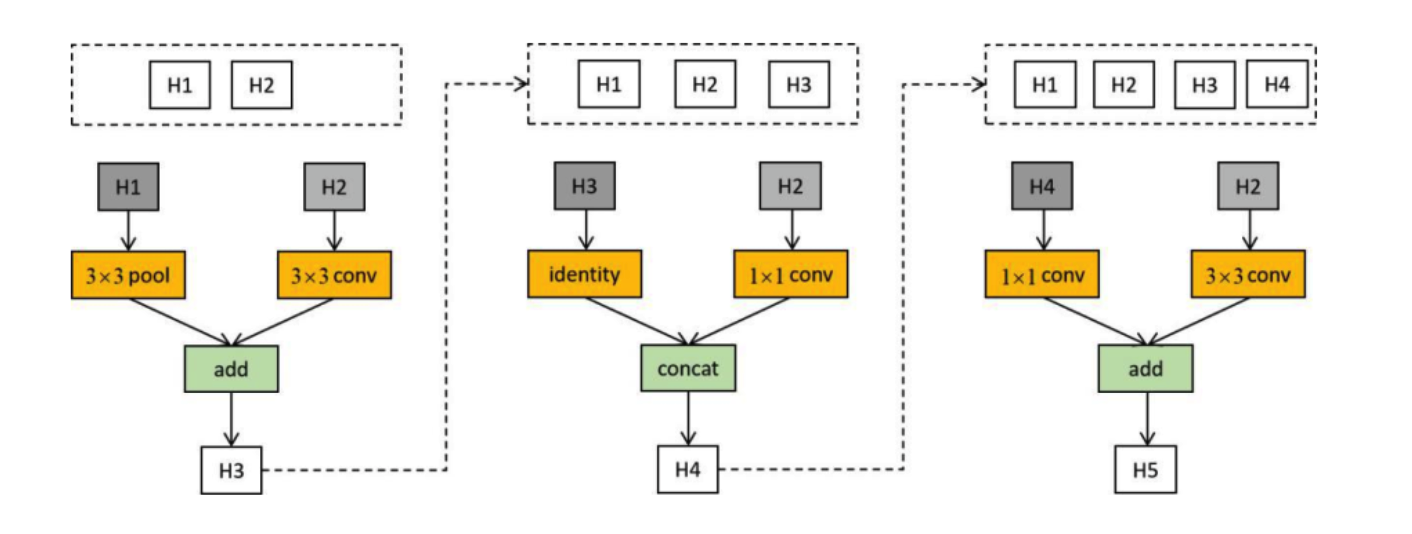
第一个隐藏层的输出和第二个隐藏层的输出作为输入,第一个block组成后,输出h3,合并入前两个隐藏层的输出作为第二个block的备选输入,最后生成h4重复以此,最终的block数目是人为划定的参数,比如说block=5,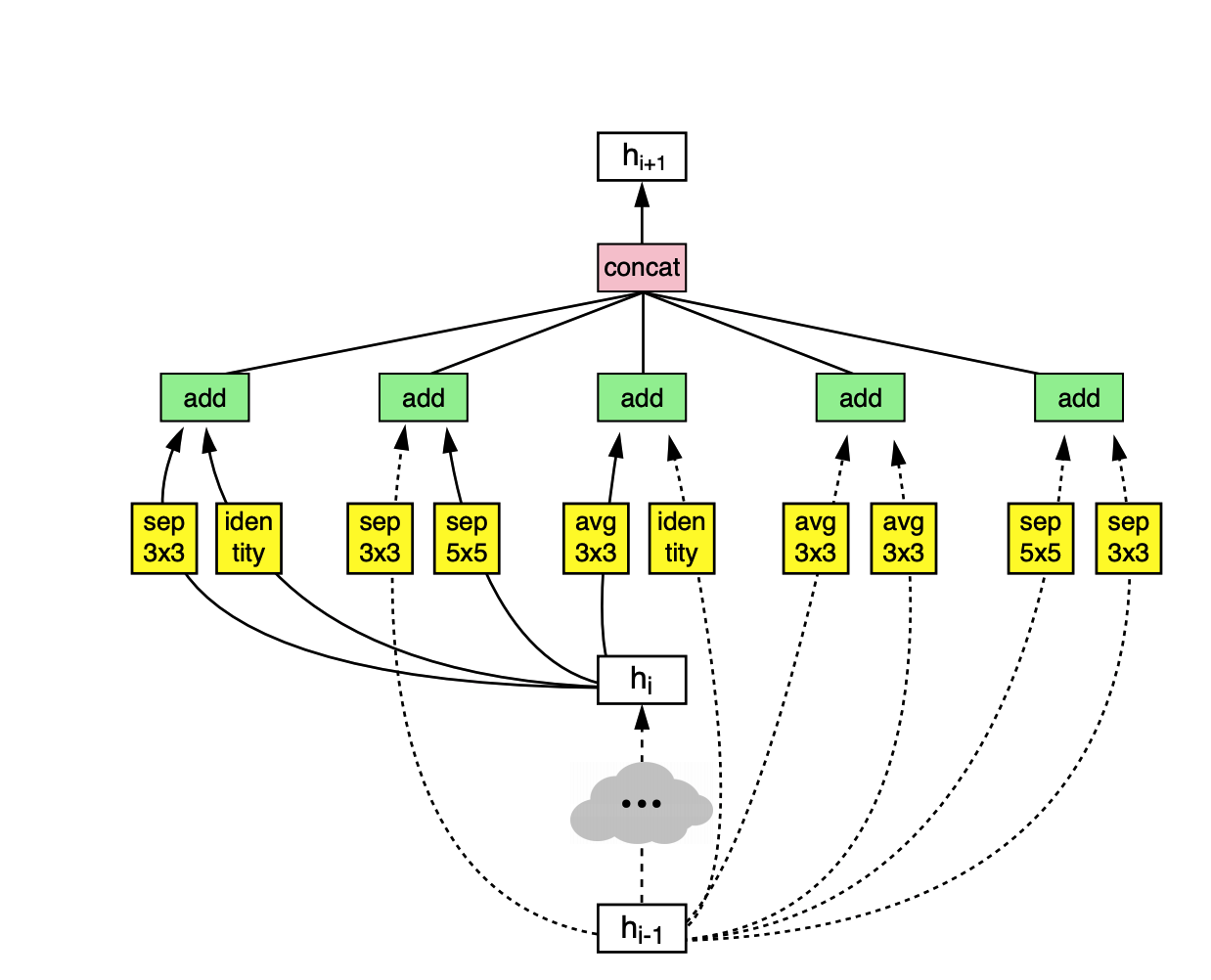
h0和h1组成第一个block的输入,h0经过identity函数(输入等于输出),h1经过3x3的多深度可分离卷积结构,之后采用add得到第一个block的输出,同理h1被选作第二个block的输入,以此类推,这就是一个normal Cell的生成过程。
以下是一个Reduction Cell的生成过程。
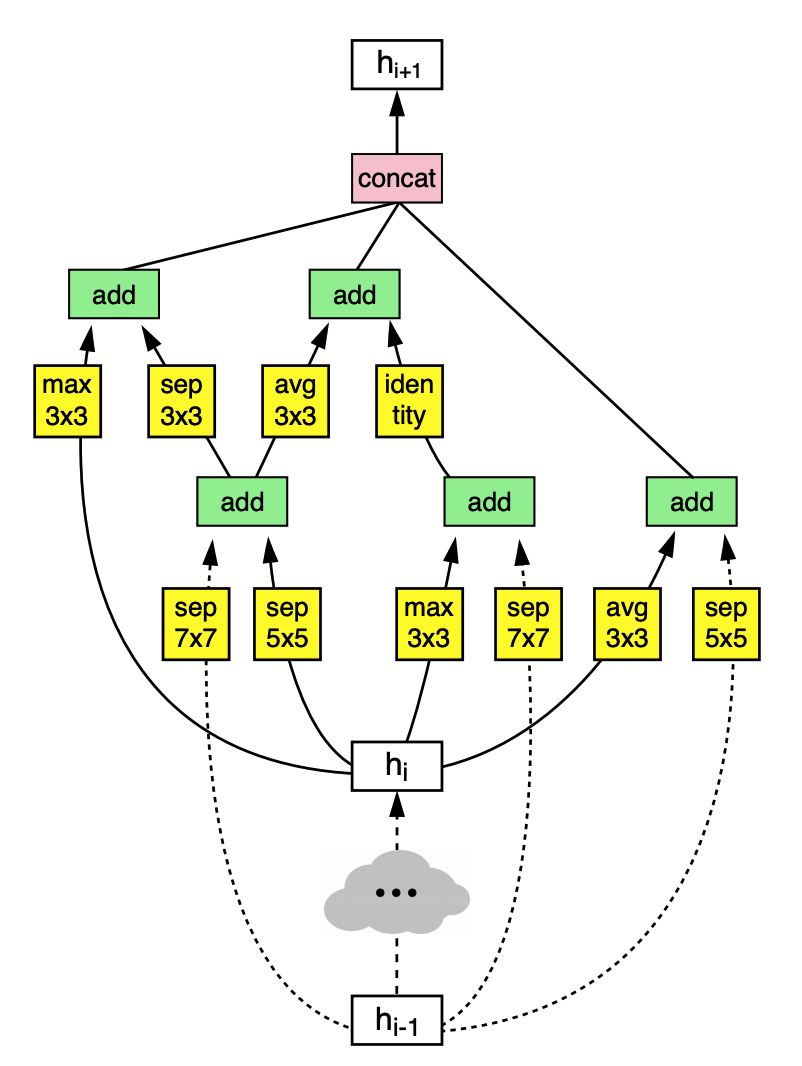
以上是一个Reduction Cell的生成过程,每一个基本的block对应两个黄色的基本算子和一个绿色的组合算子,每一个RNN都可以生成两种操作的任意一种,最后进行堆叠,如下:
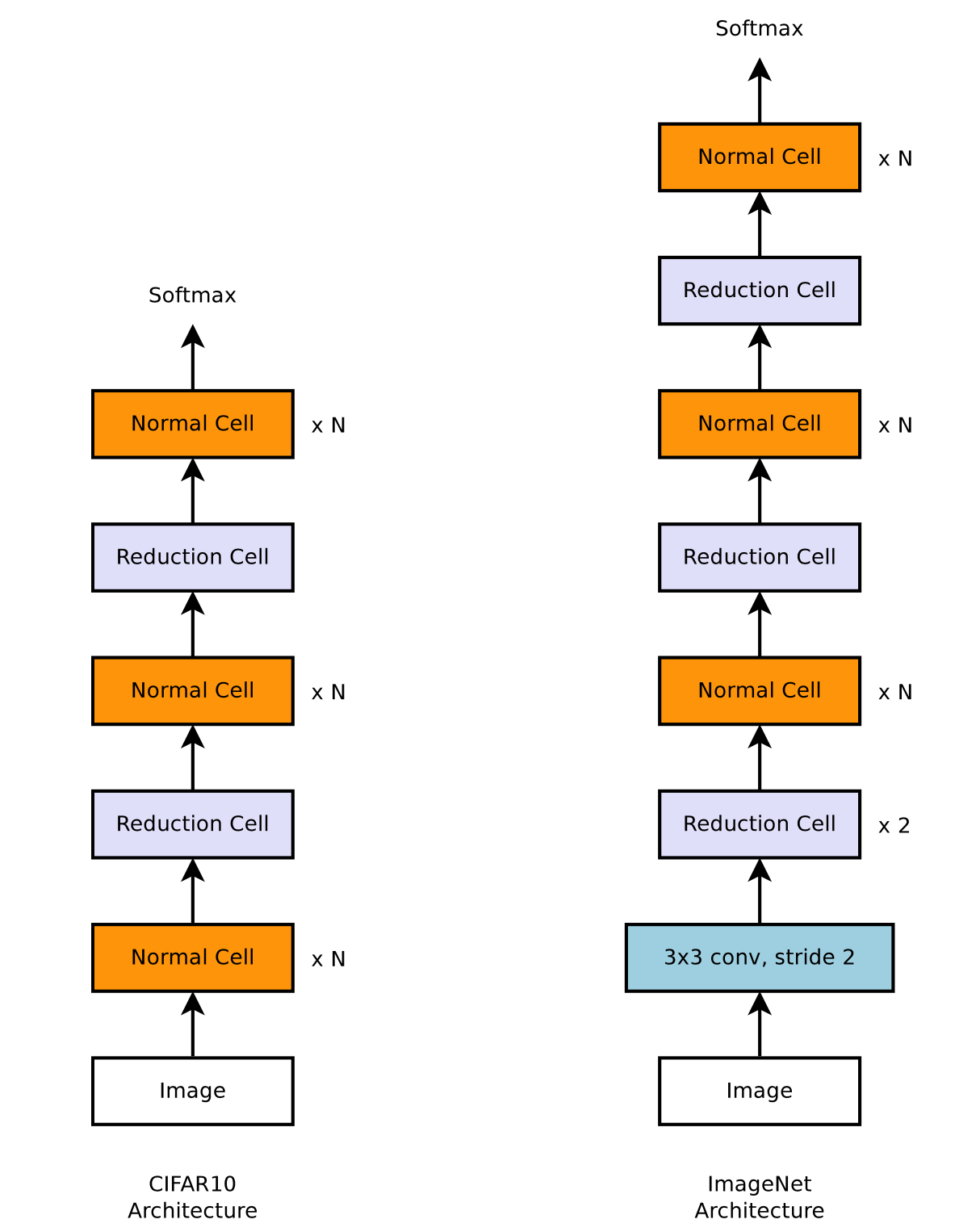
网络在两种不同的数据集上的堆叠结构不同。
效果:
准确率和计算量曲线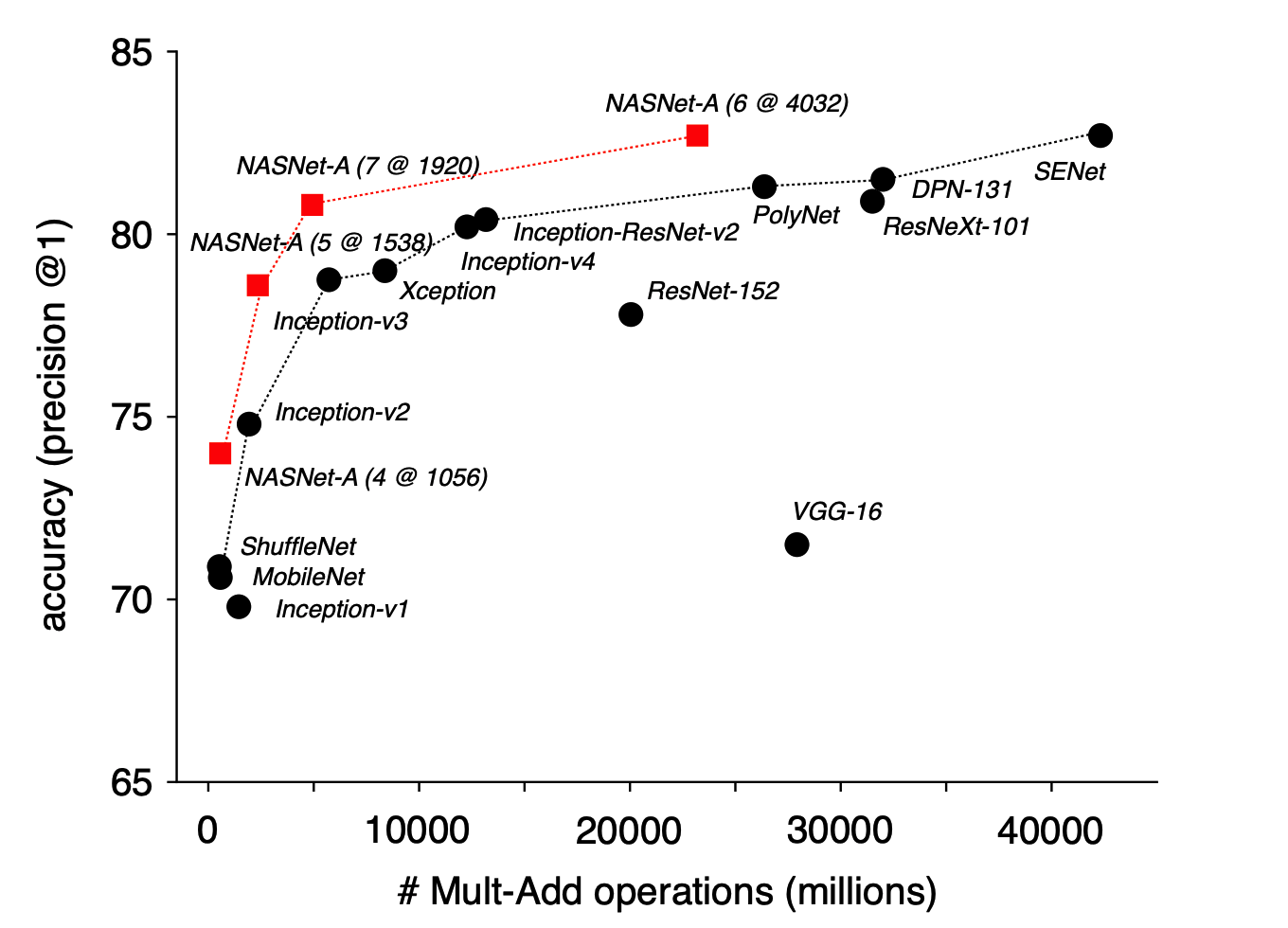
准确率和参数量曲线
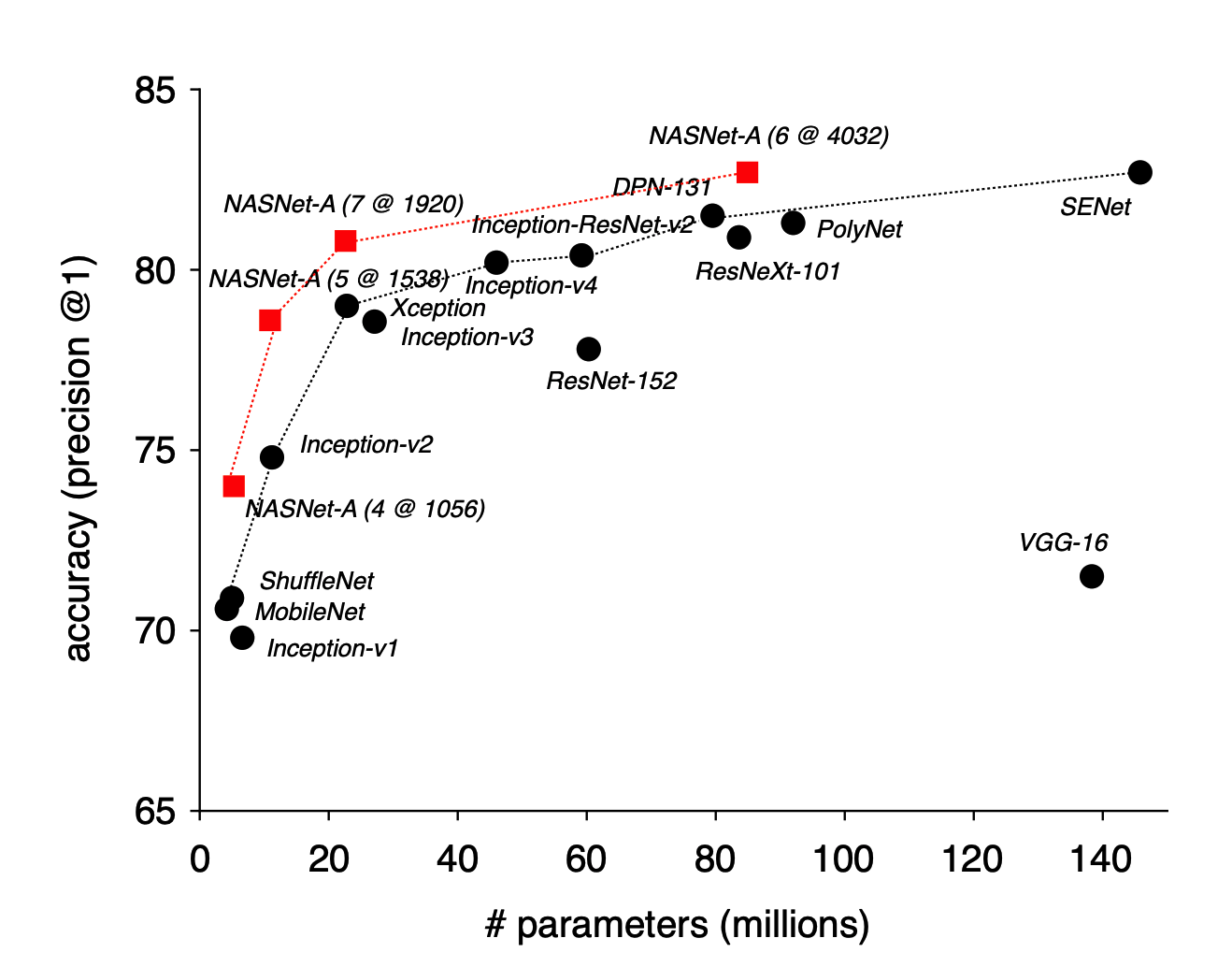
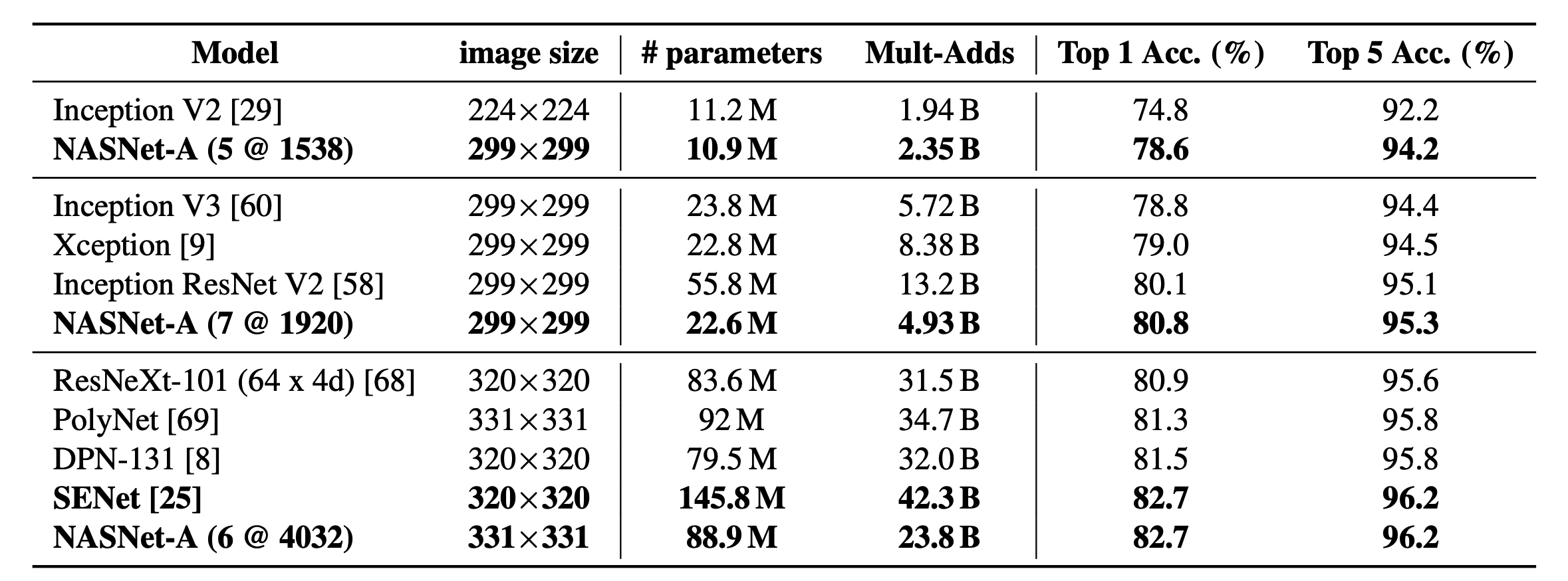
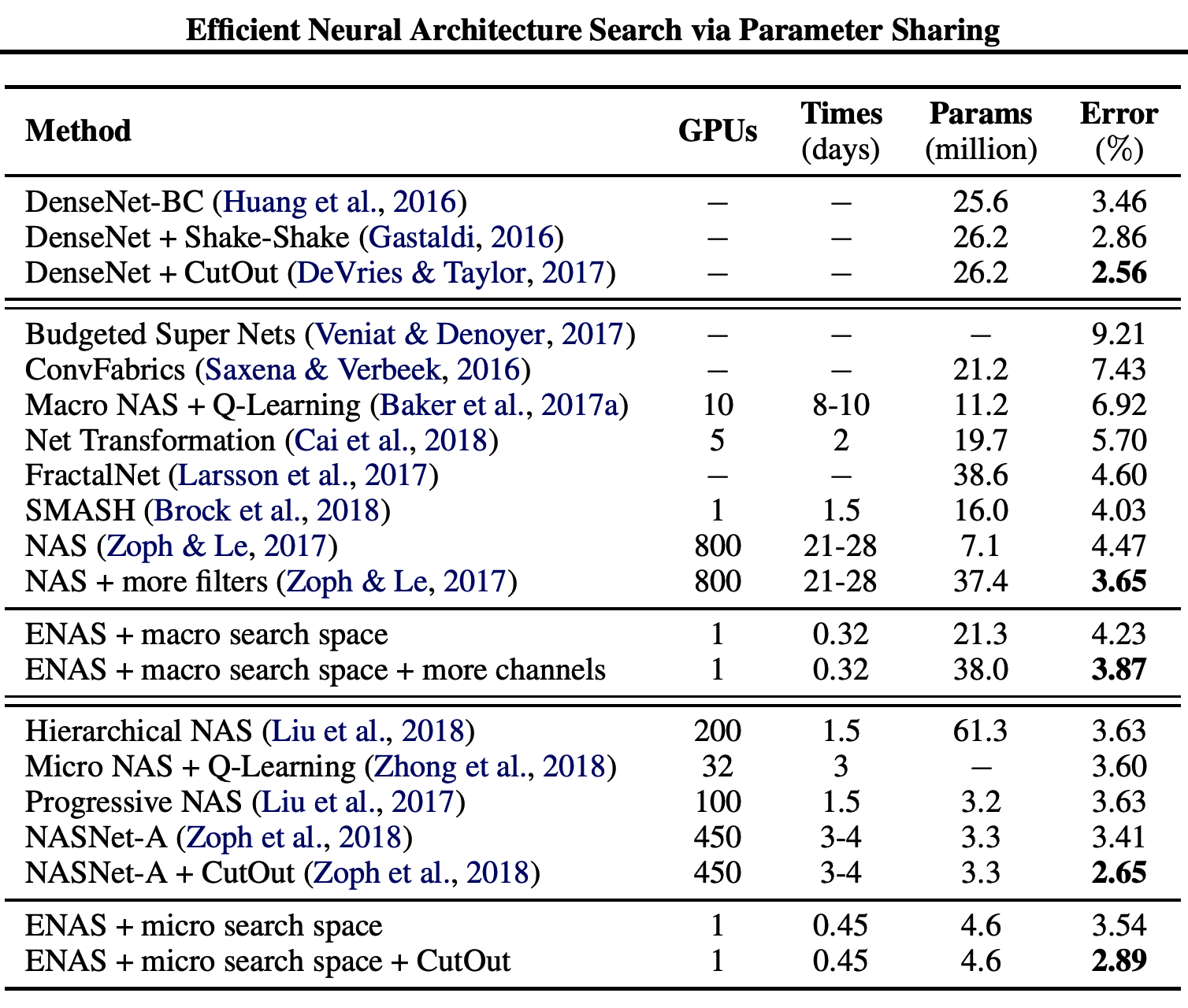
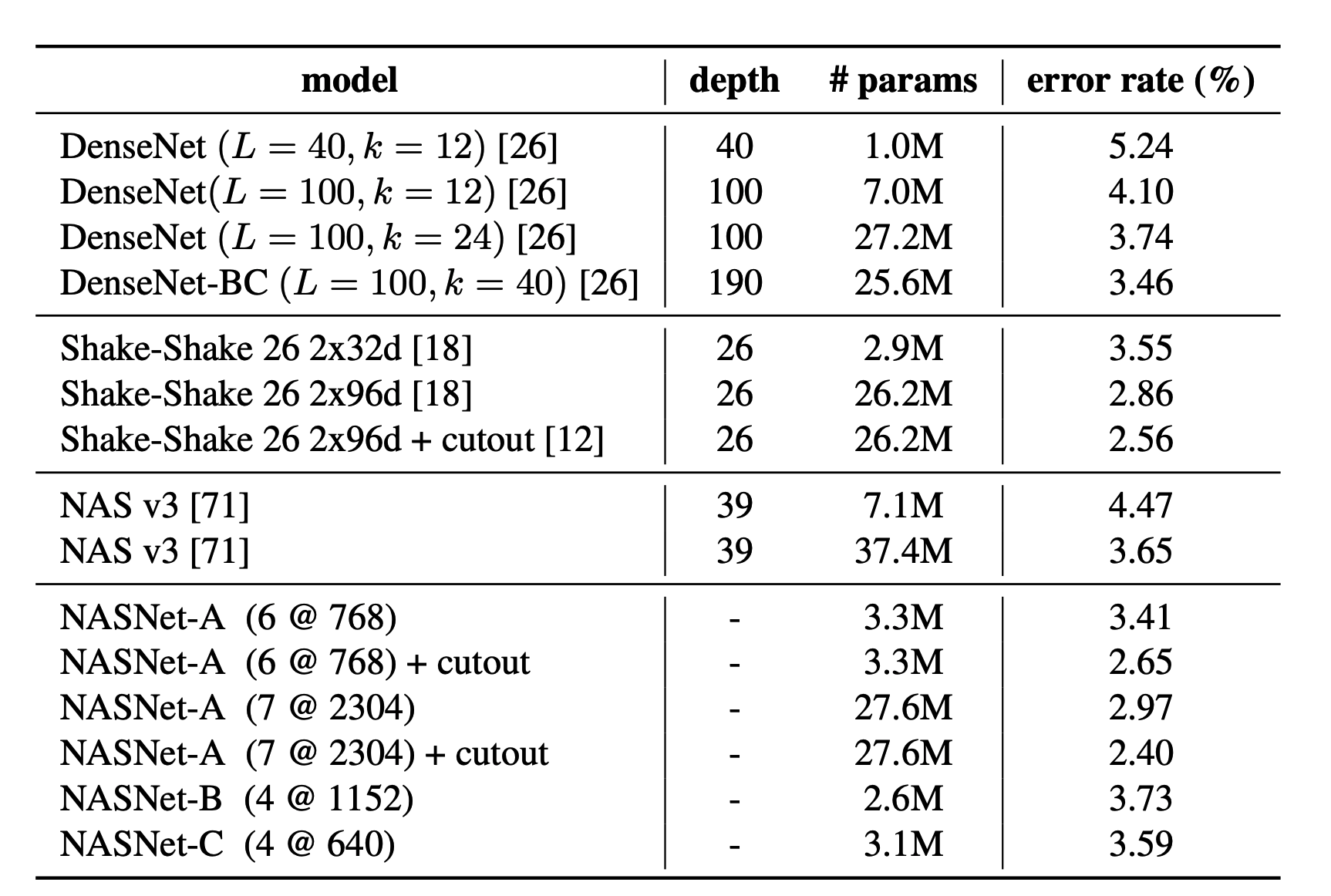
最大规模的NASnet-A在top1acc下达到了82.7,持平了未公开的模型senet,比公开的最好模型高了1.2个点,
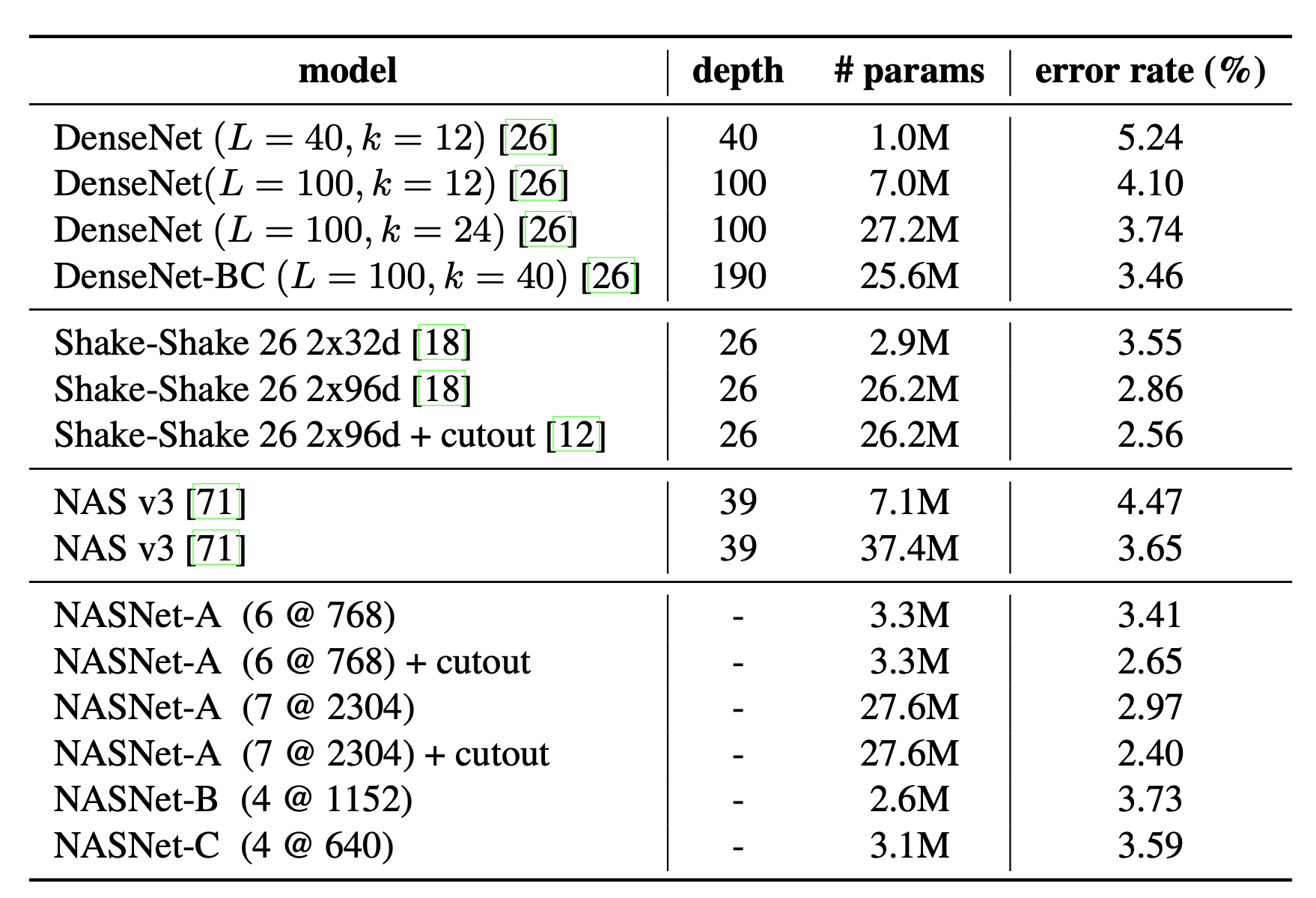
NASNet-A(7@2304) 模型将错误率降低至 2.4%,超越了包括 DenseNet 和 Shake-Shake 在内的现有模型。其中,7代表 N=7,2304代表卷积神经网倒数第二层的过滤器数量为2304。
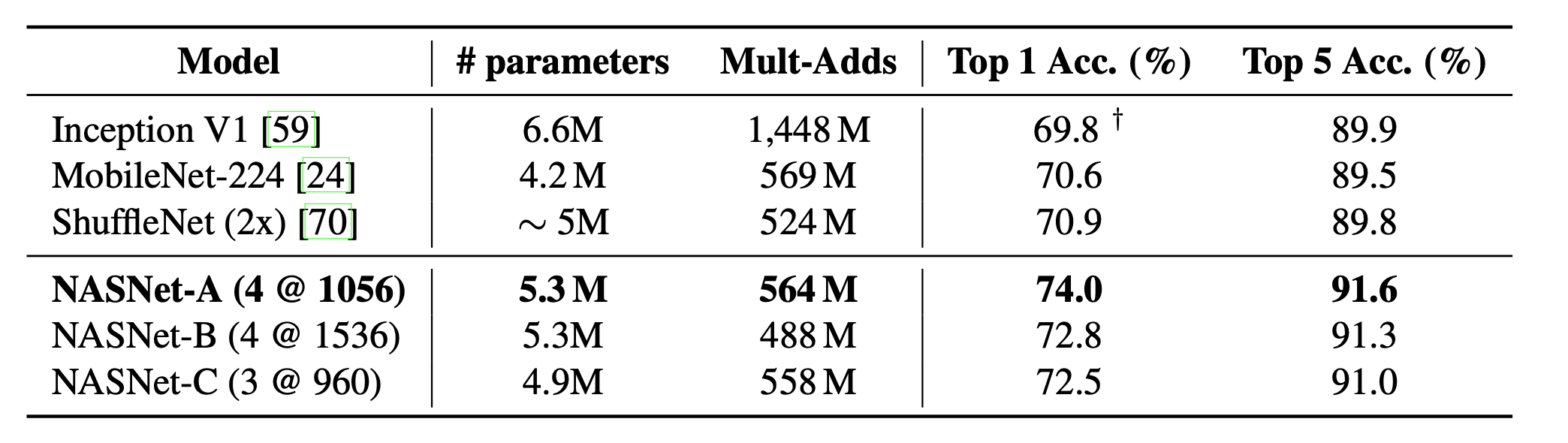
限制参数情况下,NASnet系列网络取得了比inception系列和shuffle系列更好的成绩。
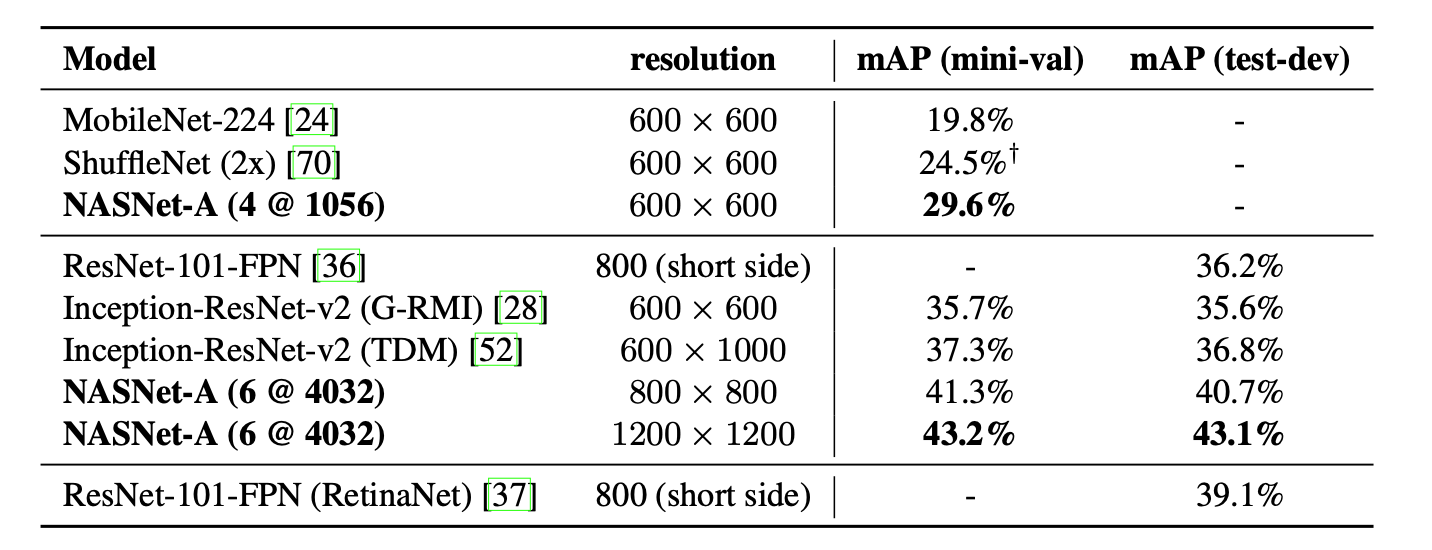
在作为目标检测任务的backbone下,NAS也比大多数网络体现出更好的适应性,(fasterR-cnn)作为框架。
ENAS
定义搜索空间
ENAS的思路是将目前神经网络的搜索架构表现为有向无环图,即输入为有边射入,输出为有边射出,节点为处理算子的形式
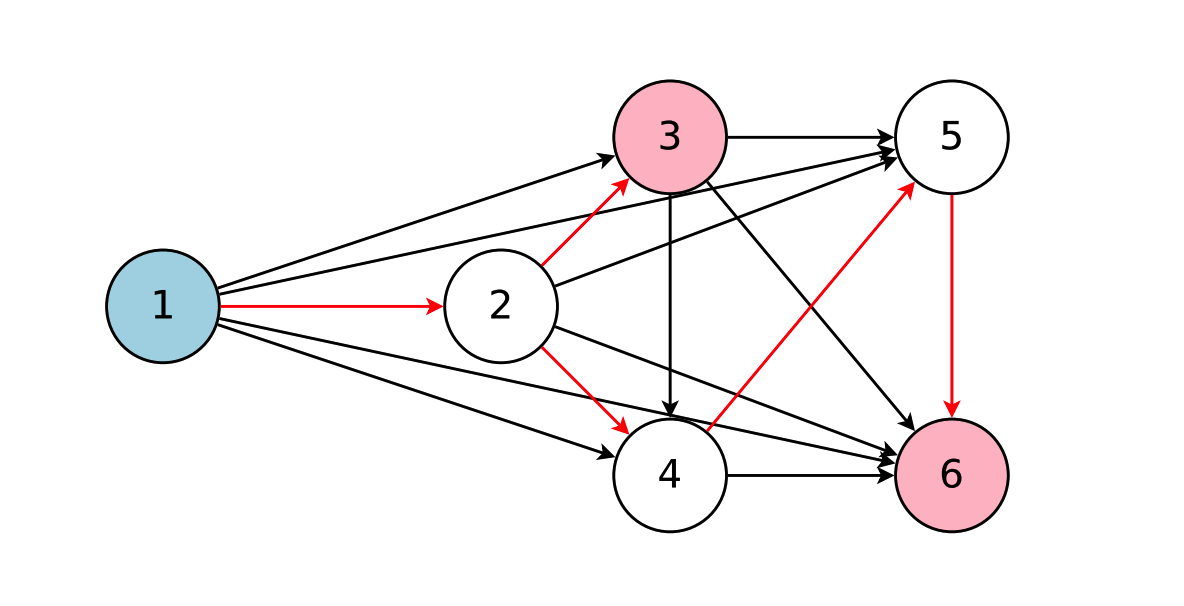
完整的搜索空间就是所有点的联结组合,节点1作为输入节点,3和6节点都是模型的输出节点,这些都是由控制器决定,
ENAS使用一个RNN(称为controller)决定每个节点的计算类型和选择激活哪些边,ENAS中使用节点数为12的搜索空间,计算类型为tanh, relu, identity, sigmoid四种激活函 数,所以搜索空间有 约 种神经网络架构。
搜索过程
例如有四个节点的搜索空间:

控制器主要选择两组策略,一个是选择前驱节点即,数据来源,二是选择操作算子。
例如:控制器选择输出节点1的算子为tanh(经过softmax输出tanh的概率最高),节点2的前置节点为1,激活函数为RELU,节点3的前置节点为2,依然是RELU,节点4的前置节点为1,激活函数为tanh,那么其生成过程如图。
节点1的输出为,第二个节点的输出为,第三个节点计算过程为,w的下标表示不同节点,NODE4:,这一套参数,即,在整个模型训练过程中是共享的,但是需要注意的是,并不是所有节点的权重都能直接导入使用,数据流向不一样的时候参数是没办法共享的,即如果你是一个3x3的conv操作,那么其实你做不到的就是把一个conv5x5的卷积核参数交给他去初始化,所以会重新初始化一个新的参数,在下一次出现5x5的卷积核的时候用上这个参数,这就是Efficient的共享权重的基础。
设计卷积网络
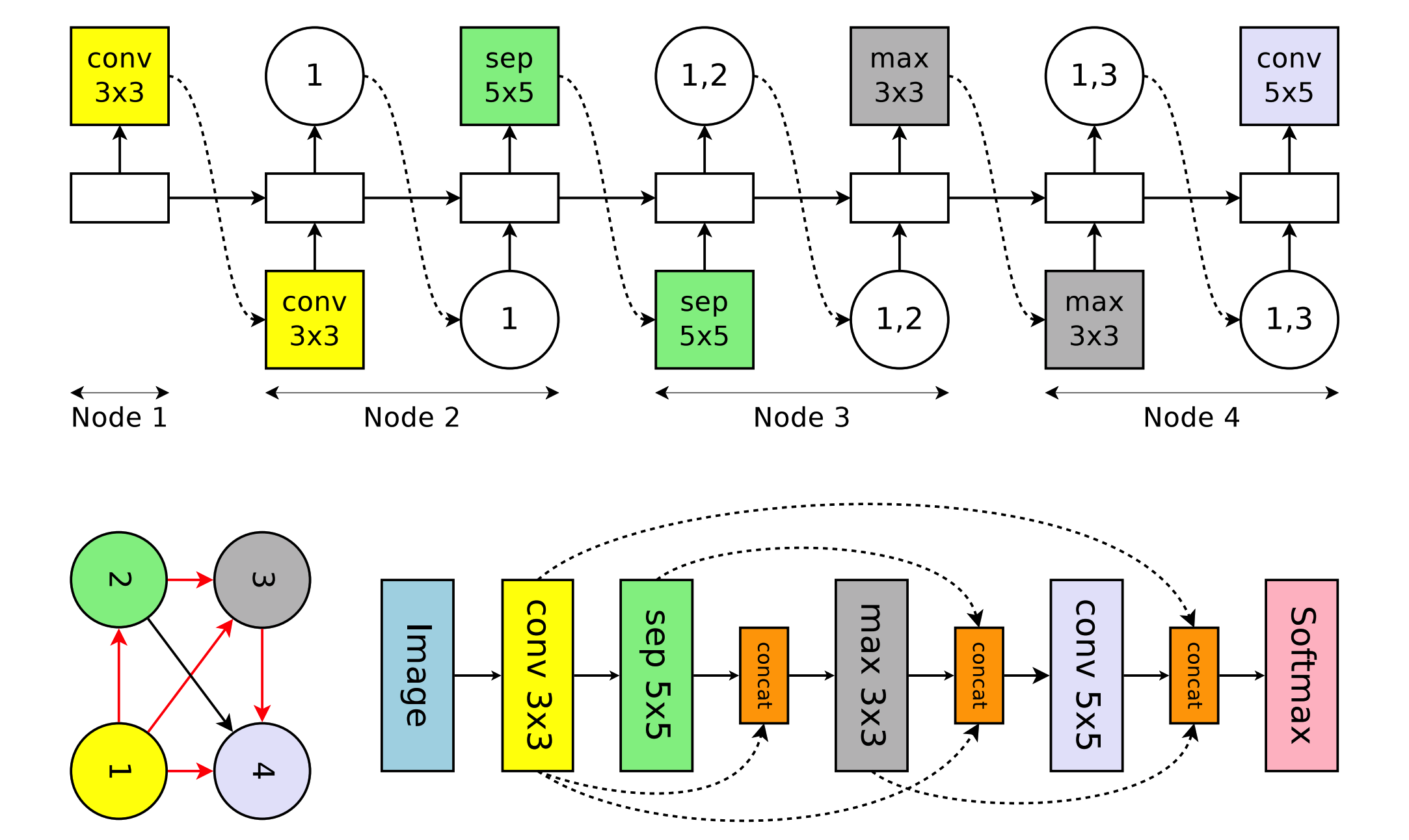
生成cnn的结构,需要做出两个决策,一个是和前面哪些节点连接,另一个是使用哪些算子构造卷积层
第一个可以产生skip connect,第二个参数可以实现不同算子的选择(3x3大小卷积、5x5大小卷积、3x3大小的可分离卷积、5x5大小可分离卷积、3x3的最大池化、3x3的平均池化)n次得到n层的网络,搜索空间中共有,因为在第n层,可以选择和前面的n-1层中的任意一层相连。
设计卷积的block
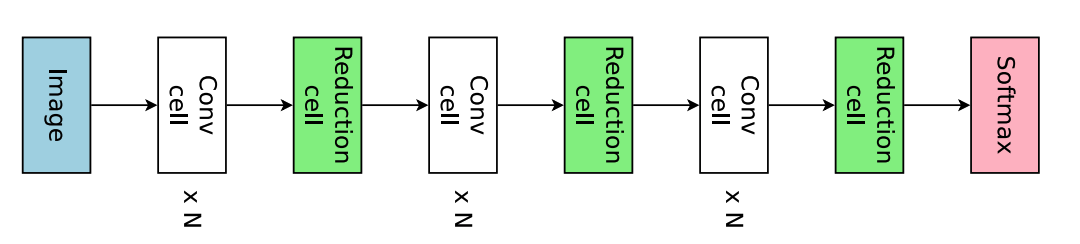
例如上图:整个网络由3个block构成,每一个block由N个conv cell和一个Reduction cell组成,最后形成总的网络架构。
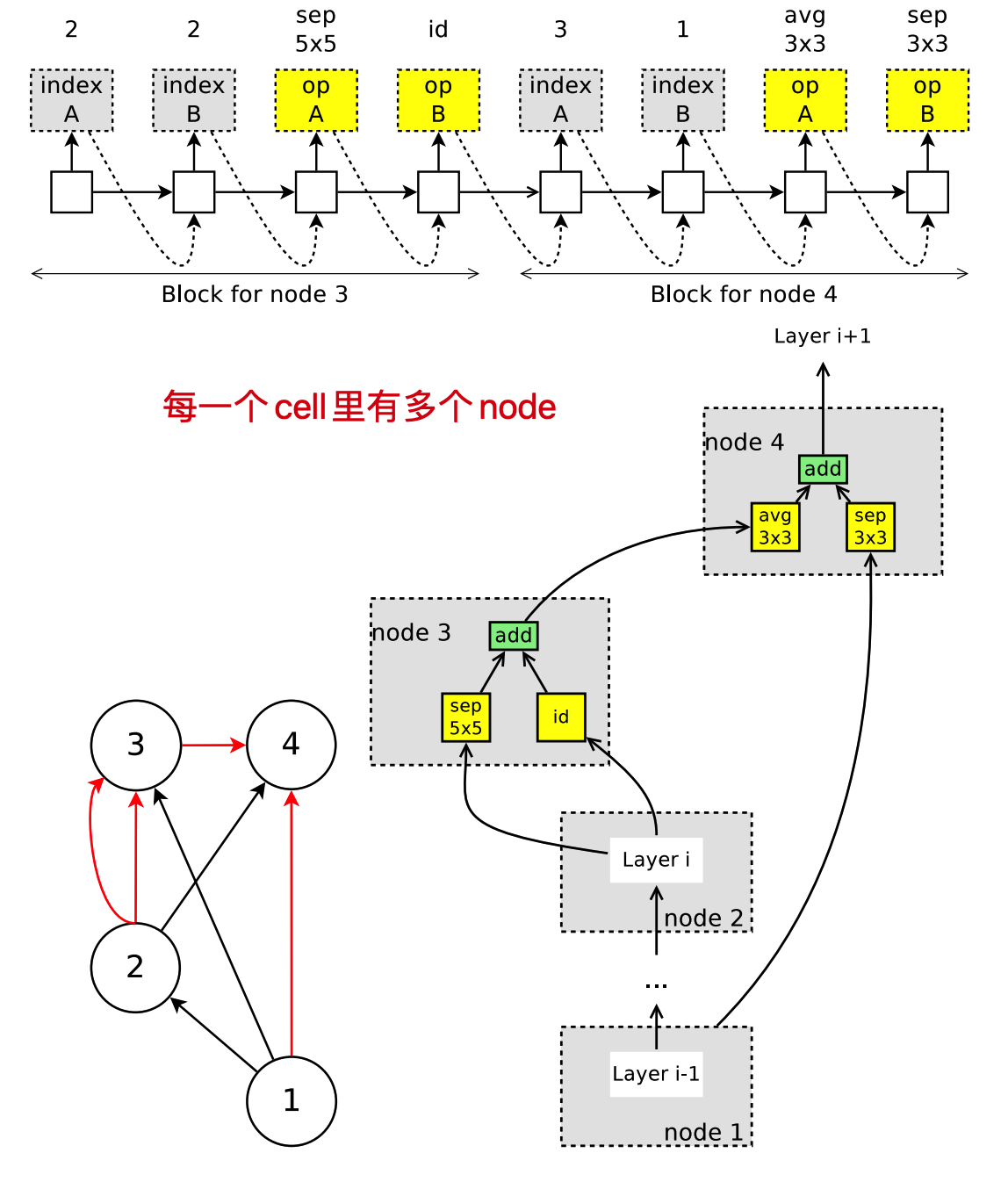
每一个conv cell里有多个节点 ,每个节点的操作不同,例如上图中,节点一和节点二作为输入,不做计算,节点三选择了两个前驱节点和两种操作,分别是identify和5x5的深度可分离卷积,所以s3=sep_conv 。
节点四同样的我们可以知道一个结构是采用了3x3的平均池化层,输入是h3,加上一个h2的直接连接,即h4 = avg_pool_3x3 ,H4就作为了当前cell的输出。
ENAS 生成的所有模型节点数是一样的,而且节点的输入和输出都是一样的,所有模型的所有节点的所有权重都是可以加载来复用的,因此我们只需要训练一次模型得到权重后,让各个模型都去验证集做一个预估,只要效果好的说明发现了更好的模型了。实际上这个过程会进行很多次,而这组共享的权重也会在一段时间后更新,例如我找到一个更好的模型结构了,就可以用这个接口来训练更新权重,然后看有没有其他模型结构在使用这组权重后能在验证机有更好的表现。
训练细节
在ENAS中共有两组可学习的参数:
子网络模型的共享参数,用 表示
controller网络(即RNN(lstm)网络参数)
而训练ENAS的步骤主要包含两个交叉阶段:第一部训练子网络的共享参数 ;第二个阶段是训练controller的参数 。这两 个阶段在ENAS的训练过程中交替进行,具体介绍如下:
1.共享参数的训练
生成采样得到的网络以后,通过SGD算法来最小化损失函数,这里的损失函数比较特殊,只是对损失的估计,就是用一组模型,在一组训练数据集上得到的损失值,而不是所有模型在训练数据上的损失,即,loss代表交叉熵损失,m代表模型,即根据当前controler生成的模型,这个模型在一组数据集得到的损失期望,之后使用蒙特卡洛梯度估计方法,即大数法则的应用,得到期望的梯度为均值相关的一个函数,即是对梯度的无偏估计,有较大的方差。但作者发现当 的时候效果就比较好,也就是说使用从 采样到的任 意一个模型m上计算到的梯度就可以更新
2.训练controller参数θ
之后固定网络参数w,通过求解最大化期望奖励𝐸[𝑅(𝑚;𝑤)]来更新θ,参考上述强化学习的梯度估计方法。
3.总体描述
首先使用控制器生成若干模型。
之后对于每一个采样得到的模型,直接计算其在验证集上得到的奖励。
最后选择奖励最高的模型再次从头训练,以此往复。
结果
ENAS的结果没有NASnet好,这是因为ENAS没有像NAS那样从训练后的controller中采样多个模型架构,然后从中选出在验证集上表现最好的一个。
但是即便效果不如NAS,但是ENAS效果并不差太多,而且训练效率大幅提升。