Fasterrcnn
张一极
20210306
Faster RCNN流程:
卷积层,提取feature map
RPN生成候选区域,输出两个向量,anchor的类别信息和anchor的位置偏移信息
ROI pooling,输入feature maps和建议框以及图片缩放参数,后生成一个proposal feature maps(统一尺寸),送入全连接分类
Fullconnect,分类
1.Backbone 网络
使用ZF/VGG/RESNET/之类在imagenet上预训练过的预训练模型初始化特征提取网络。
2.RPN 网络
输入为backbone得到的feature map,通过两条支路,用1x1卷积进行训练得到两个输出:
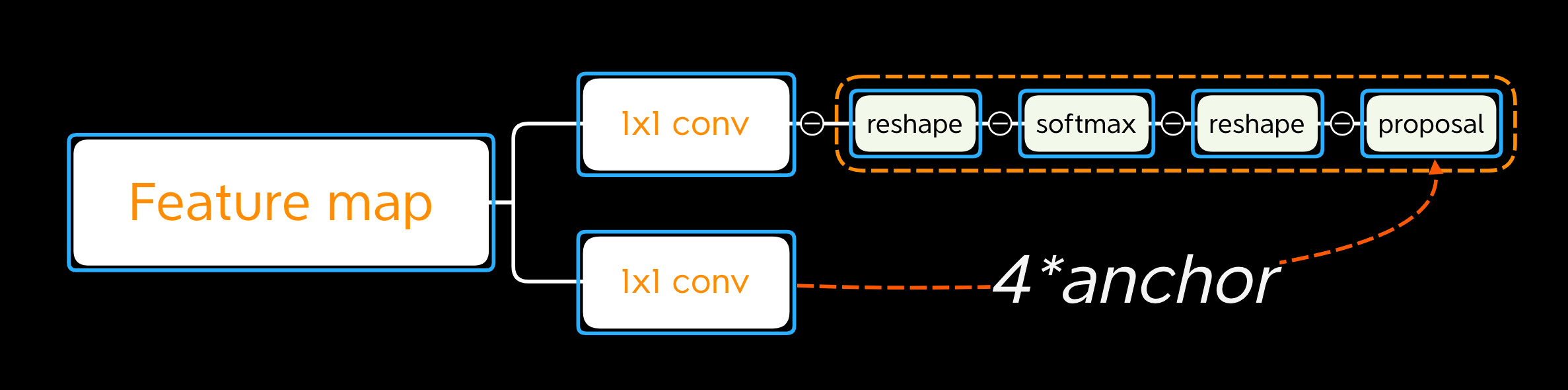
【1,2k,H,W】:代表不同anchor下的前景背景概率,交叉熵损失
细节:输入为feature map,通过1x1卷积升维为2*k维度的向量,经过softmax输出两类概率
Reshape是为了更方便softmax进行分类,先reshape成【1,2,H*k,W】,输出后再reshape回去为【1,2k,H,W】

【1,4k,H,W】:代表不同anchor与GT的回归参数(即如何变换得到GT),smooth-L1损失
细节:
通过1x1卷积升高维度为4*anchor个通道,分别代表四个回归边框的参数
边框回归参数有四个,分别代表中心点x,中心点y,宽度w,高度h,计算表达式为:
- 位置信息参数:
- 宽高信息参数::
- 损失函数:Smooth
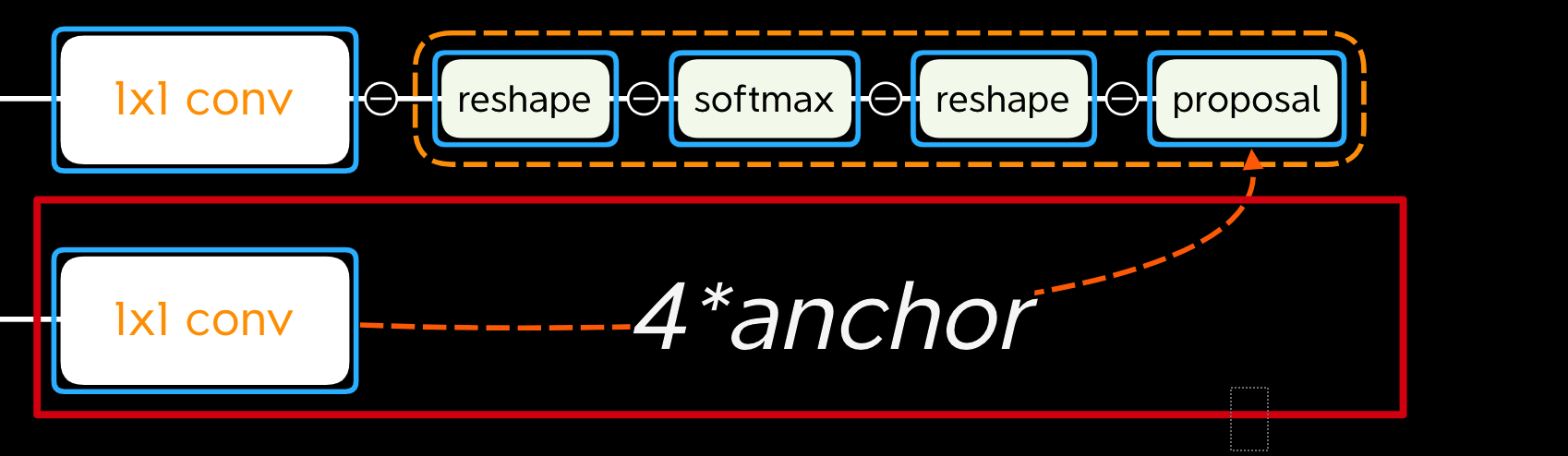
3.Propasals layer
RPN会得到很多propasals,送入propasals layer进行筛选:
输入有三个:
- 【1,2k,H,W】代表不同anchor下的前景背景概率
- 【1,4k,H,W】代表不同anchor与GT的回归参数(即如何变换得到GT)
- im_info:记录了图像信息,记录anchor缩放参数(M/16*N/16)
- 生成anchor,与RPN中进行训练的anchor一致,接着使用参数进行修正anchor位置,得到第一版本的候选区域,接着输入
- 按照第一个分类向量【1,2k,H,W】,排出最高分数的anchor,限定尺寸/剔除小尺寸anchor/NMS非极大值抑制
- 对每个GT,两个策略,1.选择iou最高的一个anchor作为正样本,2.选择iou大于0.7的anchor作为正样本,正样本个数不超过128个
- 随机选择与GT的iou小于0.3的anchor作为负样本,正负样本总数不超过256(正样本少负样本就多,总数固定)
为样本分类的概率值, 为样本的标定值(label), anchor为正样本时 为1,为负样本时 为0, 为两种类别的对数损失(log loss)
可以看得出来,只关注了正样本的回归损失,一般为256,一般为(60*40的feature map尺寸:2400),一般取10,平衡回归损失和分类损失
整个fasterrcnn的损失和RPN网络类似,依然是分类损失和回归损失,最终联合训练(原论文是分开训练)
区别是RPN网络的分类损失为二分类(前景,背景)损失,总体损失函数的分类损失为多分类损失
Smooth—L1
- 附TF的L1实现:
xxxxxxxxxxdef _smooth_l1_loss(self, bbox_pred, bbox_targets, bbox_inside_weights, bbox_outside_weights, sigma=1.0, dim=[1]):sigma_2 = sigma ** 2box_diff = bbox_pred - bbox_targets #ti-ti*in_box_diff = bbox_inside_weights * box_diff #前景才有计算损失的资格abs_in_box_diff = tf.abs(in_box_diff) #x = |ti-ti*|smoothL1_sign = tf.stop_gradient(tf.to_float(tf.less(abs_in_box_diff, 1. / sigma_2))) #判断smoothL1输入的大小,如果x = |ti-ti*|小于就返回1,否则返回0#计算smoothL1损失in_loss_box = tf.pow(in_box_diff, 2) * (sigma_2 / 2.) * smoothL1_sign + (abs_in_box_diff - (0.5 / sigma_2)) * (1. - smoothL1_sign)out_loss_box = bbox_outside_weights * in_loss_boxloss_box = tf.reduce_mean(tf.reduce_sum(out_loss_box,axis=dim))return loss_box4.ROI pooling
输入:
- 原图经历backbone的feature map
- 剩下脱颖而出的bboxes
将feature map通过均分为NxN大小的方格,每一个grid进行max pooling,得到NxN大小的向量,Flatten展平处理后输入分类层
把每个bbox的feature map分为N*N个区域,每个区域取一个最大值(maxpooling),输出一个N * N的向量,以实现每个不同尺寸图片输入进去后,获得同样大小的输出,适应不同尺寸输入。
xxxxxxxxxximport tensorflow as tfdef roi_pool(featureMaps,rois,im_dims):'''Regions of Interest (ROIs) from the Region Proposal Network (RPN) areformatted as:(image_id, x1, y1, x2, y2)Note: Since mini-batches are sampled from a single image, image_id = 0s'''with tf.variable_scope('roi_pool'):# Image that the ROI is taken from (minibatch of 1 means these will all be 0)box_ind = tf.cast(rois[:,0],dtype=tf.int32)# ROI box coordinates. Must be normalized and ordered to [y1, x1, y2, x2]boxes = rois[:,1:]normalization = tf.cast(tf.stack([im_dims[:,1],im_dims[:,0],im_dims[:,1],im_dims[:,0]],axis=1),dtype=tf.float32)boxes = tf.div(boxes,normalization) #在这里归一化框的坐标boxes = tf.stack([boxes[:,1],boxes[:,0],boxes[:,3],boxes[:,2]],axis=1)# (x1, y1, x2, y2)变为(y1, x1, y2, x2)# ROI pool output sizecrop_size = tf.constant([14,14]) #输出尺寸# ROI poolpooledFeatures = tf.image.crop_and_resize(image=featureMaps, boxes=boxes, box_ind=box_ind, crop_size=crop_size)# Max pool to (7x7)pooledFeatures = tf.nn.max_pool(pooledFeatures, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')return pooledFeatures5.最后分类层
输出两个目标:
- 更精准的bboxes
- 准确的类别信息
并联两条路

输出:
bboxes
class_info
end
20210307